Research¶
Preprint¶
(2022) L. Van Hoorebeeck, and P.-A. Absil, “Quadproj: a Python package for projecting onto quadratic hypersurfaces”. (preprint)
(2021) L. Van Hoorebeeck, P.-A. Absil, and A. Papavasiliou, “Projection onto quadratic hypersurfaces”, submitted. (
preprint, abstract/BibTex)
Thesis¶
Journal papers¶
(2022) L. Van Hoorebeeck, P.-A. Absil, and A. Papavasiliou, “Non-Convex Economic Dispatch with Valve-Point Effects and Losses with Guaranteed Accuracy”, International Journal of Electrical Power & Energy Systems (JEPE), Volume 134, January 2022, https://doi.org/10.1016/j.ijepes.2021.107143. (
preprint, abstract/BibTex, code, doc)(2020) L. Van Hoorebeeck, P.-A. Absil, and A. Papavasiliou, “Global Solution of Economic Dispatch with Valve Point Effects and Transmission Constraints”, Electric Power Systems Research, Volume 189, 2020, ISSN 0378-7796, https://doi.org/10.1016/j.epsr.2020.106786. (
preprint, abstract/BibTex, code)
Refereed conference papers¶
(2020) L. Van Hoorebeeck, P.-A. Absil, and A. Papavasiliou, “Global Solution of Economic Dispatch with Valve Point Effects and Transmission Constraints,” 2020 Power Systems Computation Conference (PSCC), Porto, Portugal, 2020. (
preprint, abstract/BibTex, code)(2019) L. Van Hoorebeeck, P.-A. Absil, and A. Papavasiliou, “MILP-Based Algorithm for the Global Solution of Dynamic Economic Dispatch Problems with Valve-Point Effects,” 2019 IEEE Power & Energy Society General Meeting (PESGM), Atlanta, GA, USA, 2019, pp. 1-5. (
preprint, abstract/BibTex, IEEE Xplore)(2019) L. Van Hoorebeeck, J. Cavillot, H. Bui-Van, F. Glineur, C. Craeye, and E. de Lera Acedo, “Near-field calibration of SKA-Low stations using unmanned aerial vehicles,” 13th European Conference on Antennas and Propagation (EuCAP), Krakow, Poland, 2019, pp. 1-5. (abstract/BibTex, IEEE Xplore)
Code¶
Research Problems¶
Economic Dispatch¶
I am currently interested in the economic dispatch problem (EDP), this problem consists in the optimal allocation of the committed [1] generating units to meet the system load at lower cost. The objective function is the sum of each unit \(g \in G\) fuel cost at each time step \(t \in T\). Mathematically it reads,
of course I need to specify the cost functions. In my case, I want to model a physical effect, the valve point loading effect (VPE) which naturally occurs in large gaz power plant such as combined cycle gas turbines (CCGT): when a turbine is loaded at a valve point, that is just before the next valve is opened, the production is optimal, but when a turbine is loaded off a valve point, that is just after the opening of the valve, then the throttling losses increase. This sudden changes in the objective raises computational challenges. Here we model this effect with the following objective function
The following plot (in blue) gives an idea of how this function looks like.
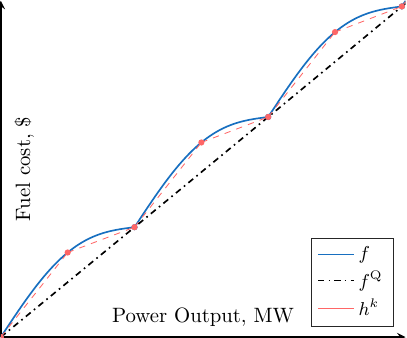
Figure 1: A term of the objective function for a given generator \(g\) at time \(t\).¶
This function is the sum of a smooth quadratic part (\(f^{\text{Q}}\)) and a nonsmooth and nonconvex rectified sine (\(f^{\text{S}}\)), and the devil lies in the later. Since the function is nonconvex, it is really difficult to prove the optimality of a point that we think is optimal and because of the nonsmoothness, we cannot use the vast amount of methods using first and second order information. Basically, the best algorithms and convergence theorems in optimization start with the sentence:
Here, we will need some tricks to tackle this problem. This will be explained soon, but first let’s look at the constraints.
Feasible Set¶
The set of constraints can be split into two categories: operational constraints, which consists in making sure that any solution is physically possible. It includes power ranges, ramp rates, network constraints and so on. The second class of constraints are the economic constraints which enforce the fact that we meet the demand and the reserve at each timestep.
Most of these constraints are boring linear ones, which means that they can easily be tackled. Considering the non boring constraints, we can first talk about the network constraints, some models of the network constraints consider are nonconvex and a lot of work is currently done to integrate these nonconvex model or other semidefinite programming (SDP) and second-order cone (SOC) relaxations. The second non boring constraint I can think of is the economic constraint accounting for the losses. This is often modelled as a quadratic surface, or quadric, which is also nonconvex.
Great, now we have a nonconvex nonsmooth objective and a nonconvex feasible set… How do we deal with such a problem?
Algorithm¶
How do we deal with such a problem? There are two different strategies: i) we target a fast and good solution with a heuristic and ii) we try to have some guarantees with respect to the finale solution. Here, we want to focus on the second case and therefore obtain a good solution along with a lower bound; we want to sandwich the optimal solution. The key here is to use a relaxation defined as follows.
A relaxation of a given (minimization) optimization problem is another optimization problem of a new function on a new feasible set such that the relaxed objective if an under-approximation of the original objective and the relaxed set contains the original feasible set.
Here with a slight abuse of language, I will consider separately the increasing of the feasible set (which I will call relaxation) and the under-approximation of the objective.
Under-approximation of the objective¶
Because dealing with the nonlinear objective \(f\) is difficult, we rather work on a sequence of surrogate objective functions \((h^k)_{k \in \mathbb{N}}\). This surrogate objective function is obtained as the interpolation of \(f\) given a set of initial points (called knots) \(\mathbf{X}^0\).
As \(f\) is piecewise concave and the initial set of knots contains the points of curvature change, the initial surrogate function is an under-approximation:
The idea of the algorithm is to solve the surrogate optimization problem that is obtained by solving the ED problem with the surrogate objective function (instead of the real objective \(f\)).
Indeed, we can model this problem as a mixed-integer programming (MIP) problem and then leverage the many MIP solvers (e.g., Gurobi, Cplex). Howver, there is a price to pay. The objective function value returned by the solver is an under-approximation of the global solution value.
If \(x^0\) is the solution returned by the solver for the initial surrogate problem defined with \(h^0\) and \(x^*\) is the optimal solution value , then we directly have
The first inequality comes from the optimality of \(x^0\) for the surrogate problem, the second inequality is true because our surrogate function under-approximates \(f\), and the last inequality comes from the optimality of \(x^*\).
We just sandwiched the optimal objective function value \(f(x^*)\) between two known quantities: \(h^0(x^0)\) and \(f(x^0)\) !
We can therefore compute the (initial) optimality gap \(\delta^0\), that is, the difference between the best known upper and lower bound:
If this gap is below the user prescribed tolerance, then we basically won: we found the optimal function value (Yay!). But if we want to reduce this gap, we will iterate by improving our under-approximation. This can be done by adding the obtained solution \(x^0\) to the set of knots : \(\mathbf{X}^1 = \mathbf{X^0 \bigcup \big \{ x^0 \big \}}\).
With this knot updating mechanism, we can prove the following:
For all \(k =0,1,\dots\), the function \(h^k\) under-approximates \(f\), that is, \(h^k(x) \leq f(x)\) for all \(x\).
The sequence of functions \((h^k)_{k \in \mathbb{N}}\) is increasing, that is, \(h^k(x) \leq f(x)\) for all feasible \(x\).
The sequence converge to the optimal solution value: \(\lim_{k \to \infty} \delta^k =0\).
The algorithm is depicted in the following gif (but remember that we have several units and therefore a separate sum of 1D function).
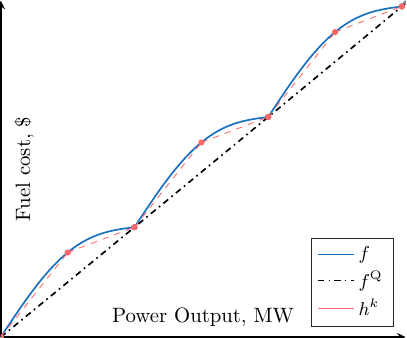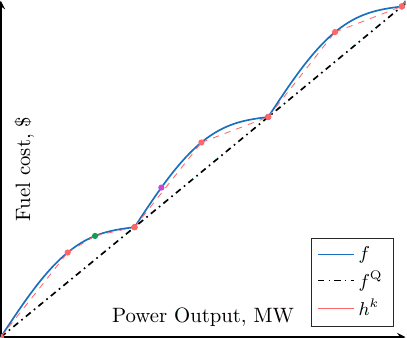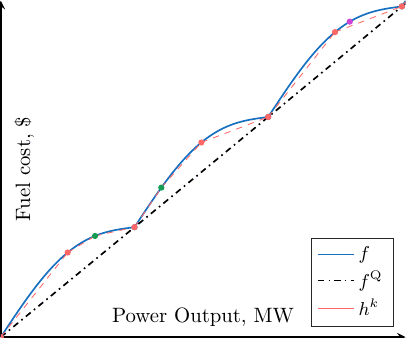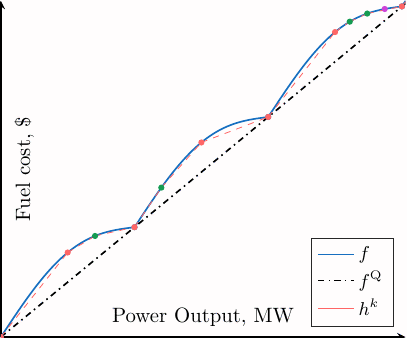
Going further¶
This is the paper that details this algorithm, denoted as the adaptive piecewise-linear approximation (APLA).
A heuristic of the algorithm is given in this paper.
The algorithm (and heuristic) is adapted to deal with transmission constraints in this paper and coupled with a Riemannian subgradient descent scheme (APLA-RSG).
Footnotes